Our Approach
CNS-Bench is the first benchmark enabling robustness evaluation w.r.t. realistic and continuous nuisance shifts, scalable to any number of classes and shifts. It covers 14 diverse shifts across 100 ImageNet classes (200k images at 5 severity levels).

ImageNet class-specific LoRA adapters are applied to a diffusion model, continuously modulating nuisance intensity. To close the distribution gap between diffusion-generated images and ImageNet, we apply textual inversion to learn class-specific embeddings and adapters.
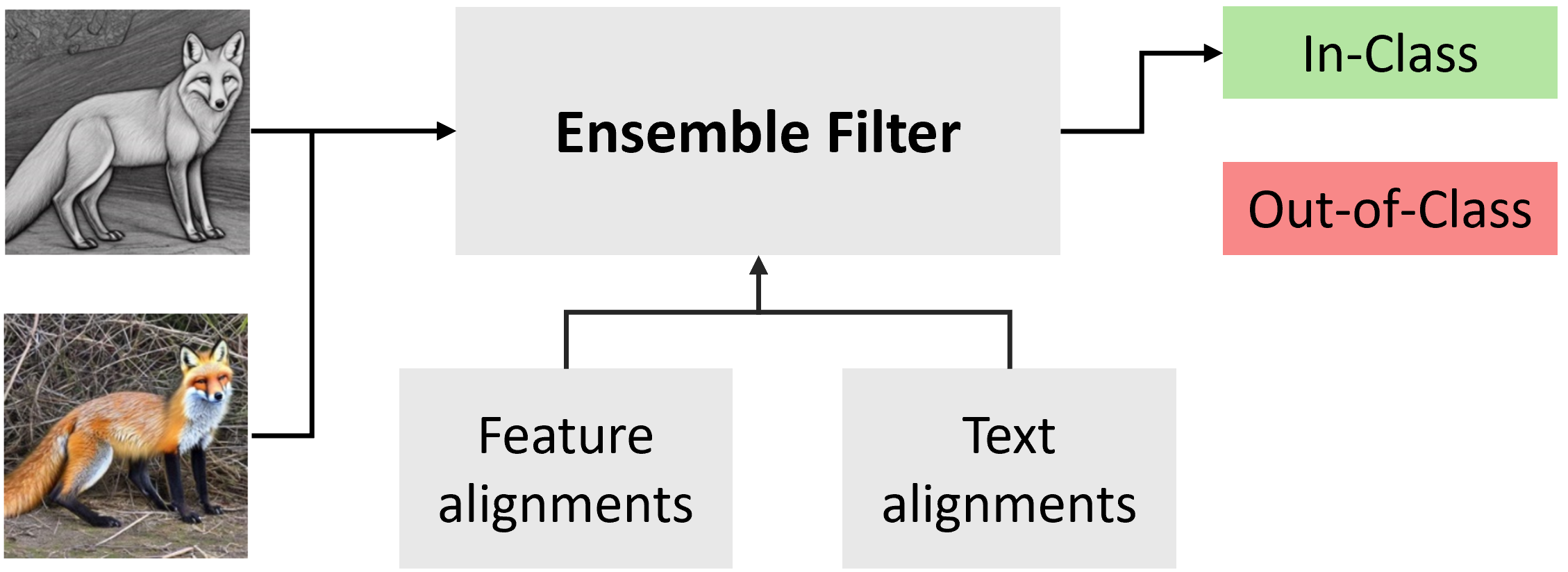
Out-of-class samples are filtered via an ensemble of four filters: two text-alignment scores (CLIP with base and shifted prompts) and two image-feature similarity scores (CLIP and DINOv2 CLS token), calibrated on a human-annotated dataset. Our filter achieves substantially larger filter accuracy than previous CLIP-based strategies.