
|
|
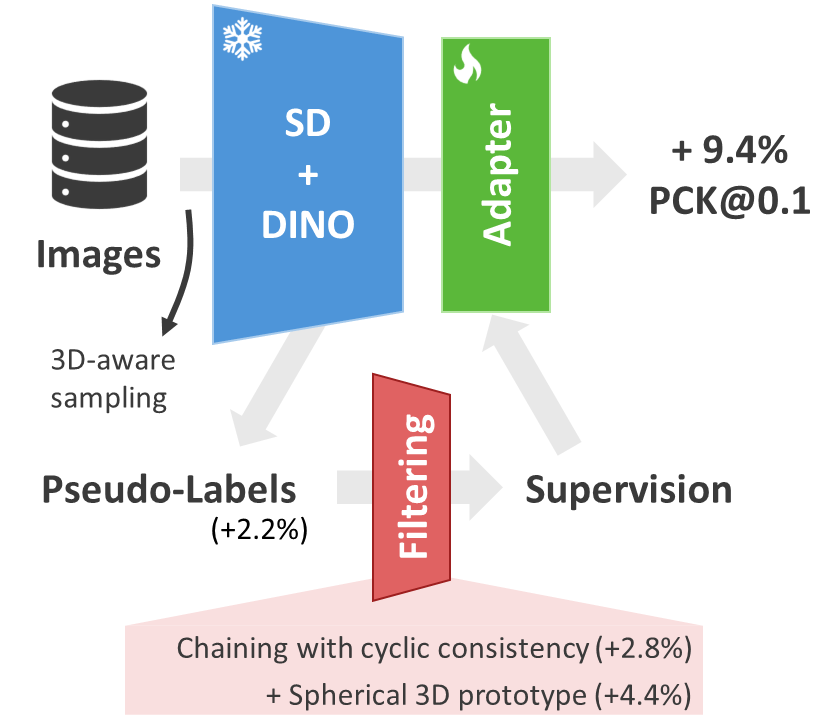
| DIY-SC finds semantic correspondences for extreme appearance and shape changes. | Feature refinement with filtered pseudo-labels brings significant improvements. |
Try DIY-SC directly in your browser — upload two images and explore semantic correspondences.
Finding correspondences between semantically similar points across images and object instances is one of the everlasting challenges in computer vision. While large pre-trained vision models have recently been demonstrated as effective priors for semantic matching, they still suffer from ambiguities for symmetric objects or repeated object parts. We propose to improve semantic correspondence estimation via 3D-aware pseudo-labeling. Specifically, we train an adapter to refine off-the-shelf features with pseudo-labels obtained via 3D-aware chaining, filtering wrong labels through relaxed cyclic consistency, and 3D spherical prototype mapping constraints. While reducing the need for dataset specific annotations compared to prior work, we set a new state-of-the-art on SPair-71k by over 4% absolute gain and by over 7% against methods with similar supervision requirements. The generality of our proposed approach simplifies extension of training to other data sources, which we demonstrate in our experiments.
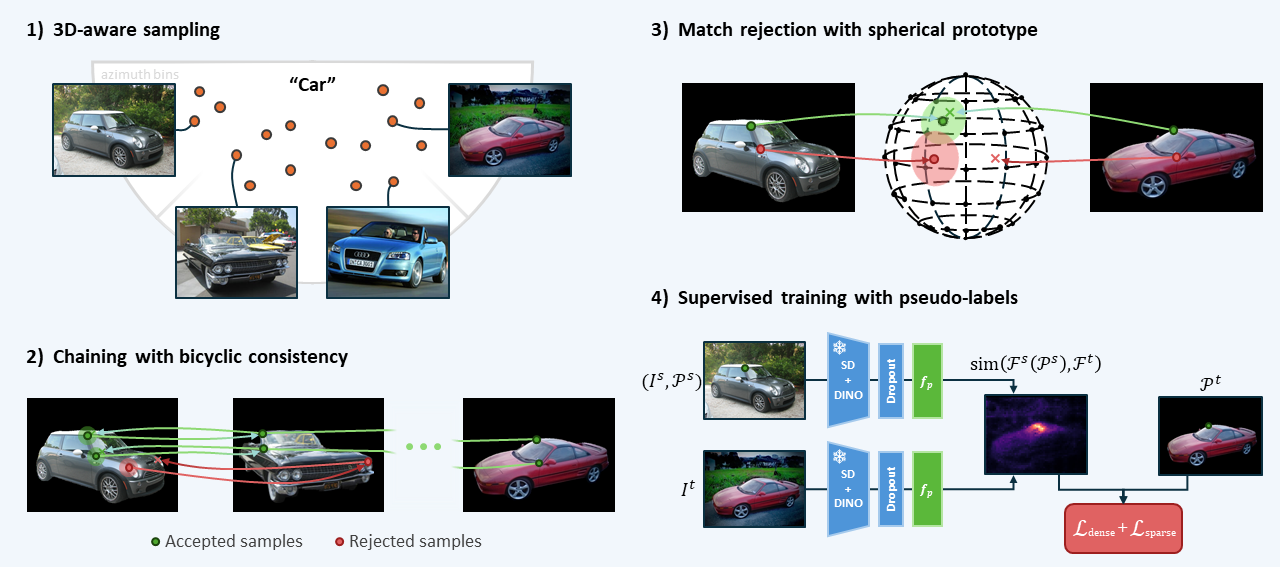
Method overview. We use azimuth information to sample image pairs for which higher zero-shot performance can be expected (1). We then chain the pairwise predictions to get correspondences for larger viewpoint changes, where we reject matches that do not fulfill a relaxed cyclic consistency constraint (2). We further filter pseudo-labels by rejecting pairs that cannot be mapped to a similar location on a 3D spherical prototype (3). Finally, we use the resulting pseudo-labels to train an adapter in a supervised manner (4). This approach does not require keypoint annotations and is, therefore, easily scalable to larger datasets, which we demonstrate by pre-training on ImageNet-3D and fine-tuning on SPair-71k.
| Method | SPair-71k | AP-10k (PCK@0.1) | ||||
|---|---|---|---|---|---|---|
| @0.1 | @0.05 | @0.01 | I.S. | C.S. | C.F. | |
| Zero-shot | ||||||
| SD + DINOv2 | 59.9 | 44.7 | 7.9 | 62.9 | 59.3 | 48.3 |
| DistillDIFT* (U.S.) | 60.8 | 45.4 | 8.0 | — | — | — |
| Weakly supervised | ||||||
| SphMap† | 64.4 | 48.2 | 8.4 | 65.4 | 63.1 | 51.0 |
| TLR | 65.4 | 49.1 | 9.9 | 68.7 | 64.6 | 52.7 |
| DistillDIFT* (W.S.) | 65.3 | 49.8 | 8.9 | — | — | — |
| Ours | 71.6 | 53.8 | 10.1 | 70.6 | 69.1 | 57.8 |
| Ours (DINOv2 only) | 70.6 | 51.1 | 9.0 | 71.2 | 69.8 | 58.3 |
| Fully supervised | ||||||
| TLR (sup) | 82.9 | 72.6 | 21.6 | 70.1 | 68.3 | 58.4 |
PCK per image. Bold = best, underlined = second best among non-supervised methods. AP-10k: intra-species (I.S.), cross-species (C.S.), cross-family (C.F.). † SphMap evaluated with our 2-sphere configuration on ImageNet-3D. * DistillDIFT uses dataset-specific keypoint label definitions. DINOv2 only: adapter trained on DINOv2 features without SD.
Ablations on SPair-71k. Each component brings a significant improvement; the baseline is the SD+DINOv2 zero-shot approach.
| Pseudo-labels | Cyc. cons. | Relaxed c.c. | Chaining | Sph. rej. | PCK@0.1 |
|---|---|---|---|---|---|
| 65.0 | |||||
| ✓ | 67.2 | ||||
| ✓ | ✓ | 66.9 | |||
| ✓ | ✓ | 68.4 | |||
| ✓ | ✓ | ✓ | 70.0 | ||
| ✓ | ✓ | 72.9 | |||
| ✓ | ✓ | ✓ | ✓ | 74.4 |
Pre-training on ImageNet-3D (86k images) and fine-tuning on SPair-71k further boosts performance, demonstrating the scalability of the weakly-supervised training strategy.
| Model | SPair-71k | AP-10k I.S. | AP-10k C.S. | AP-10k C.F. |
|---|---|---|---|---|
| Ours (SPair) | 71.6 | 70.6 | 69.1 | 57.8 |
| Ours (IN3D) | 68.0 | 67.8 | 65.8 | 53.3 |
| Ours (IN3D → SPair) | 72.2 | 71.1 | 69.4 | 58.1 |
PCK@0.1 per image. AP-10k splits: intra-species (I.S.), cross-species (C.S.), cross-family (C.F.).
Four challenging SPair-71k examples where prior SOTA methods mostly fail. Green = correct match, red = incorrect.

Bus. Appearance change, repeated object parts.

Car. Appearance change, repeated parts, viewpoint change.

Motorbike. Viewpoint change, feature ambiguity in background.

Person. Left-right ambiguity, semantically similar categories.
Columns (left to right): SphMap, TLR, DistillDIFT (W.S.), Ours.

UMAP feature visualization. The features encode 3D-aware semantic information.

Exemplary tracking. DIY-SC-refined features result in more stable tracking compared to DINOv2.
Adam Kortylewski acknowledges support via his Emmy Noether Research Group funded by the German Research Foundation (DFG) under Grant No. 468670075. Thomas Wimmer is supported through the Max Planck ETH Center for Learning Systems.
@inproceedings{duenkel2025diysc,
title = {Do It Yourself: Learning Semantic Correspondence from Pseudo-Labels},
author = {D{\"u}nkel, Olaf and Wimmer, Thomas and Theobalt, Christian and Rupprecht, Christian and Kortylewski, Adam},
booktitle = {ICCV},
year = {2025}
}